一分钟长的文生视频大模型Sora,如此逼真。OpenAI再次震惊了世界。
一分钟长的视频,是更漫长的征程的开端。OpenAI称他们所做的事情,是构建一个“物理世界的通用模拟器”。

Sora生成的电影预告片
OpenAI网站上的技术报告,主要提供了训练Sora的方法,以及对其能力和局限性的定性评估。技术报告的13位作者中,有4位华人。
报告也明确地说,不提供模型和实现细节。尤其是公众和监管者最关注的数据来源。但是,这篇报告所列举的32篇参考论文,已经提供了所有的方法和技术。
OpenAI用一句话概括:“我们利用了一种在视频和图像潜码的时空块上操作的transformer架构”。
具体点说就是:这帮大牛训练了一个网络,用于降低视觉数据的维度。许多专家认为其视频来源是Youtube。这个网络以原始视频为输入,输出一个在时间和空间上都被压缩的潜在表示。Sora在这个压缩的潜在空间内接受训练,随后也在此空间内生成视频。他们还训练了一个相应的解码器模型,将生成的潜码映射回像素空间。
应该掌握四个关键词:潜码(latent code),时空块(spacetime patches),扩展 (scaling),通用模拟器 (general purpose simulators)。
许多之前的研究已经通过各种方法研究了视频数据的生成模型,包括循环网络、生成对抗网络、自回归变换器和扩散模型。这些工作通常专注于视觉数据的一个狭窄类别、较短的视频,或者固定大小的视频。Sora是一个视觉数据的通用模型——它可以生成跨越不同持续时间、宽高比和分辨率的视频和图像,最长可达一分钟的高清视频。
Sora是一个扩散模型;给定输入的噪声块(和条件信息,如文本提示),它被训练用于预测初始的“干净”块。重要的是,Sora是一个扩散Transformer,在多个领域展示了显著的扩展性能,包括语言建模、计算机视觉和图像生成。
Sora能够适应宽屏1920x1080p视频、竖屏1080×1920视频以及它们之间的所有格式。这使得Sora能够直接以不同设备的原生宽高比创建内容。它还允许我们在使用相同模型以全分辨率生成之前,快速原型化较小尺寸的内容。
简单地说,OpenAI集大成了先前的技术,而其中的每一项技术,都有过论文介绍,OpenAI在前人及同行研究的基础之上,构建出Sora,一个非常重要的原因,是他们坚信数据-Transformer-扩展-涌现这一法则。下面是所有的参考论文及其为Sora所用之处:
Srivastava, Nitish, Elman Mansimov, 和 Ruslan Salakhudinov. “使用LSTMs进行视频表示的无监督学习.” 国际机器学习会议. PMLR, 2015.
Chiappa, Silvia, 等. “循环环境模拟器.” arXiv预印本 arXiv:1704.02254 (2017).
Ha, David, 和 Jürgen Schmidhuber. “世界模型.” arXiv预印本 arXiv:1803.10122 (2018).
(注:1-3,许多之前的研究已经通过各种方法研究了视频数据的生成模型,包括循环网络 )
Vondrick, Carl, Hamed Pirsiavash, 和 Antonio Torralba. “生成具有场景动态的视频.” 神经信息处理系统进展 29 (2016).
Tulyakov, Sergey, 等. “MoCoGAN: 分解运动和内容以生成视频.” IEEE计算机视觉和模式识别会议论文集. 2018.
Clark, Aidan, Jeff Donahue, 和 Karen Simonyan. “在复杂数据集上生成对抗视频.” arXiv预印本 arXiv:1907.06571 (2019).
Brooks, Tim, 等. “生成动态场景的长视频.” 神经信息处理系统会议进展 35 (2022): 31769-31781.
(注:4-7,生成对抗网络的方法与技术)
Yan, Wilson, 等. “VideoGPT: 使用VQ-VAE和transformers生成视频.” arXiv预印本 arXiv:2104.10157 (2021).
Wu, Chenfei, 等. “Nüwa: 为创造神经视觉世界进行视觉合成预训练.” 欧洲计算机视觉会议. 瑞士: 施普林格自然, 2022。
(注:8-9,自回归Transformer )
Ho, Jonathan, 等. “Imagen视频: 使用扩散模型生成高清视频.” arXiv预印本 arXiv:2210.02303 (2022).
Blattmann, Andreas, 等. “对齐你的潜码: 使用潜在扩散模型合成高分辨率视频.” IEEE/CVF计算机视觉和模式识别会议论文集. 2023.
Gupta, Agrim, 等. “使用扩散模型生成逼真视频.” arXiv预印本 arXiv:2312.06662 (2023).
(注:10-12,扩散模型,如何逼真)
Vaswani, Ashish, 等. “注意力就是你所需要的一切.” 神经信息处理系统进展 30 (2017).
Brown, Tom, 等. “语言模型是小样本学习者.” 神经信息处理系统会议进展 33 (2020): 1877-1901.
(注:13-14 ,作者从大型语言模型中受到的启发是,通过对互联网级数据进行训练,可以获得通用能力。)
Dosovitskiy, Alexey, 等. “一幅图像值16×16个词: 大规模图像识别的transformers.” arXiv预印本 arXiv:2010.11929 (2020).
Arnab, Anurag, 等. “Vivit: 视频视觉transformer.” IEEE/CVF国际计算机视觉会议论文集. 2021.
He, Kaiming, 等. “掩码自动编码器是可扩展的视觉学习者.” IEEE/CVF计算机视觉和模式识别会议论文集. 2022.
Dehghani, Mostafa, 等. “Patch n’Pack: NaViT, 适用于任何宽高比和分辨率的视觉transformer.” arXiv预印本 arXiv:2307.06304 (2023).
(注:15-18,Transformer已经被证明在在计算机视觉中显示出非凡的扩展特征,能训练出适用于任何宽高比和分辨率的视频)
Rombach, Robin, 等. “使用潜在扩散模型合成高分辨率图像.” IEEE/CVF计算机视觉和模式识别会议论文集. 2022.
(注:通过把视频压缩成为低维度的潜码空间,把视频转换为时空块 )
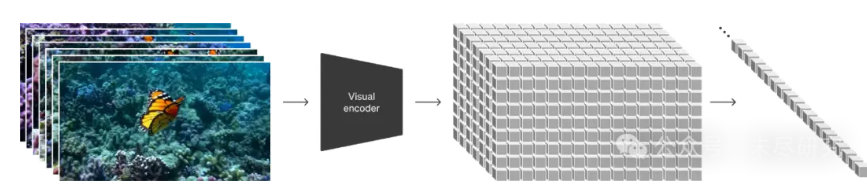
把视觉数据变成时空块
Kingma, Diederik P., 和 Max Welling. “自编码变分贝叶斯.” arXiv预印本 arXiv:1312.6114 (2013).
(注:训练出一个能减少视觉维度数据的网络)
Sohl-Dickstein, Jascha, 等. “使用非平衡热力学的深度无监督学习.” 国际机器学习会议. PMLR, 2015.
Ho, Jonathan, Ajay Jain, 和 Pieter Abbeel. “去噪扩散概率模型.” 神经信息处理系统进展 33 (2020): 6840-6851.
Nichol, Alexander Quinn, 和 Prafulla Dhariwal. “改进的去噪扩散概率模型.” 国际机器学习会议. PMLR, 2021.
Dhariwal, Prafulla, 和 Alexander Quinn Nichol. “扩散模型在图像合成上胜过GANs.” 神经信息处理系统会议进展. 2021.
Karras, Tero, 等. “阐明基于扩散的生成模型的设计空间.” 神经信息处理系统进展 35 (2022): 26565-26577.
(注:21-25, Sora是一个扩散模型,给定输入的噪声块(和条件信息,如文本提示),它被训练用于预测初始的“干净”块 )
Peebles, William, 和 Saining Xie. “用transformers扩展扩散模型.” IEEE/CVF国际计算机视觉会议论文集. 2023.
(注:Sora是一个扩散Transformer)

Transformer跨越不同的模态,其扩展功能依然有效
Chen, Mark, 等. “像素的生成预训练.” 国际机器学习会议. PMLR, 2020.
Ramesh, Aditya, 等. “零样本文本到图像生成.” 国际机器学习会议. PMLR, 2021.
(注:27-28,Transformer在图像生成方面具有非凡的扩展特征)
Yu, Jiahui, 等. “扩展自回归模型以生成内容丰富的文生图.” arXiv预印本 arXiv:2206.10789 2.3 (2022): 5.
Betker, James, 等. “用更好的图说改善图像生成.” 计算机科学. https://cdn.openai.com/papers/dall-e-3.pdf 2.3 (2023): 8
(注:29-30,使用了Dall.E3的字幕和标题技术,用于视频)
Ramesh, Aditya, 等. “使用CLIP潜码的分层文本条件图像生成.” arXiv预印本 arXiv:2204.06125 1.2 (2022): 3.
(注:30-31,用Dall.E2和Dall.E3图像生成视频)
Meng, Chenlin, 等. “Sdedit: 使用随机微分方程的引导图像合成和编辑.” arXiv预印本 arXiv:2108.01073 (2021)。
来自 未尽研究